
Der Business Case für Metadaten: Eine neue Perspektive
- Reto Schneider

- 3. März
- 3 Min. Lesezeit
Jenseits der “Daten über Daten“-Falle
Jahrelang war das Wort Metadaten der ultimative Gesprächskiller in den Vorstandsetagen. Für die meisten Führungskräfte klingt es nach digitaler Ablage – eine mühsame Back-Office-Aufgabe, die technische Teams erledigen, um die Dinge “organisiert“ zu halten.
In der heutigen Geschäftswelt steht jedoch weit mehr auf dem Spiel. Wir “organisieren“ Daten nicht mehr nur; wir versuchen Maschinen beizubringen, in unserem Namen zu denken, zu handeln und Entscheidungen zu treffen. Wenn Daten der Treibstoff dieser neuen Wirtschaft sind, dann sind Metadaten das Navigationssystem, die Raffinerie und das Sicherheitshandbuch in einem. Ohne sie ist Ihre KI kein Vermögenswert, sondern ein Haftungsrisiko.
Es ist an der Zeit, Metadaten nicht länger als “nice-to-have“ Dokumentationsprojekt zu präsentieren, sondern als das entscheidende Bindeglied zwischen Rohwerten und strategischem Überleben.
Die “Daten-Mülldeponie“ und die KI-Barriere
Der traditionelle Business Case für Daten konzentrierte sich auf das Volumen. Wir haben ein Jahrzehnt damit verbracht, gewaltige Data Lakes aufzubauen, nur um festzustellen, dass wir in Wahrheit Daten-Mülldeponien errichtet haben.
Das Problem ist nicht, dass wir zu wenig Daten haben; es mangelt uns an Kontext. Dieser fehlende Kontext führt zu drei kritischen geschäftlichen Fehlentwicklungen:
Die Vertrauenslücke: Laut aktueller Berichte aus dem Jahr 2025 (Gartner, Informatica, BARC) identifizieren über 40 % der COOs mangelnde Datenqualität als das größte Hindernis für die KI-Einführung. Wenn ein Modell “halluziniert“, liegt das oft daran, dass ihm die Metadaten fehlten, um zwischen einer Testdatei und einem finalen Produktionsdatensatz zu unterscheiden.
Die “Dark Data“-Steuer: Unternehmen ertrinken derzeit in “Dark Data“ – Informationen, die gesammelt und gespeichert, aber nie genutzt werden. Dies ist nicht nur eine verpasste Chance, sondern verursacht hohe Speicherkosten und massive Sicherheitsrisiken.
Der Flaschenhals: Data Scientists verbringen noch immer bis zu 80 % ihrer Zeit (Informatica, 2025) damit, schlicht zu verstehen, was die Daten bedeuten, bevor sie überhaupt mit dem Bau eines Modells beginnen können.
Context Engineering: Kontext als Strategie
Die “neue Perspektive“ markiert den Übergang von passiven Metadaten (einem Friedhof der Dokumentation) hin zu aktiven Metadaten (einem permanent aktiven Intelligenzsystem).
Anstatt Metadaten als statische Aufzeichnung dessen zu betrachten, was getan wurde, behandeln wir sie als die operative DNA der Organisation. Dieser Ansatz wird am besten durch den Industriestandard für Datenmanagement zusammengefasst:
“Metadaten sind die ‚Daten über Daten‘, die den notwendigen Kontext liefern, damit Daten als strategisches Asset genutzt werden können. Ohne Metadaten kann eine Organisation ihre Daten nicht als Vermögenswert verwalten.“ — DAMA International (2017), DAMA-DMBOK: Data Management Body of Knowledge (2. Auflage).
Durch den Fokus auf “Context Engineering“ stellen wir sicher, dass jeder Datenpunkt seine eigene Historie, seine "Einsatzregeln“ und seinen Qualitäts-Score mit sich führt. Wir speichern nicht nur Werte; wir speichern Bedeutung.
Den Wandel realisieren: Programmatische Governance
Wie setzen wir diese Perspektive in die Realität um? Wir verabschieden uns vom manuellen Tagging und bewegen uns hin zur programmatischen Governance:
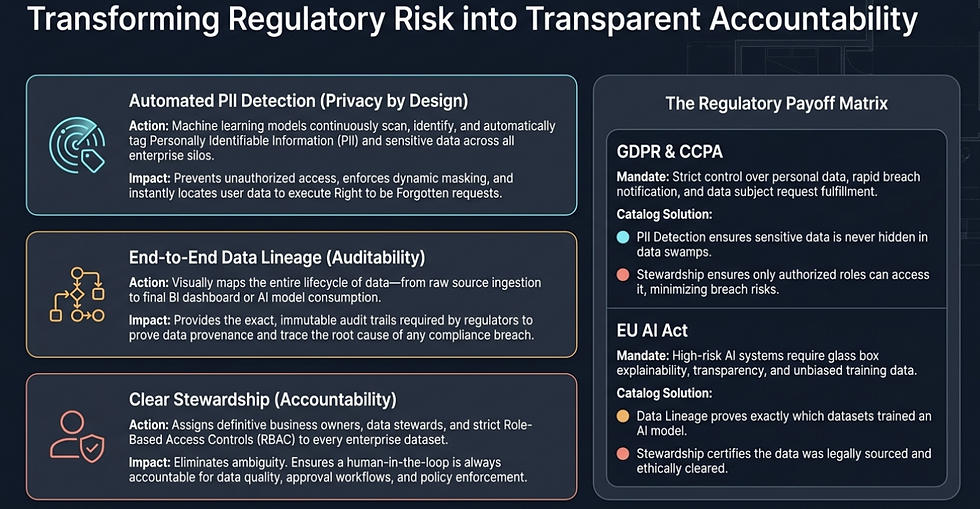
Metadaten-Automatisierung: Wir nutzen KI, um die Daten zu dokumentieren. Moderne Plattformen nutzen heute “Agentic Workflows“, um Beziehungen automatisch abzubilden, sensible personenbezogene Daten (PII) zu erkennen und die Datenherkunft (Lineage) in Echtzeit zu aktualisieren.
Governance as Code: Wir betten Metadaten-Regeln direkt in die Data Pipelines des Unternehmens ein. Wenn ein Datensatz die Anforderungen nicht erfüllt (z. B. fehlende Eigentümerschaft oder veraltete Zeitstempel), wird er nicht verarbeitet. Dies sichert “Quality by Design“ statt “Quality by Correction“.
Der Semantic Layer: Wir schaffen einen “Universalübersetzer“, in dem Geschäftsbegriffe (wie “Umsatz“ oder “Churn“) einmalig in der Metadatenebene definiert und konsistent über jedes Dashboard und jeden KI-Agenten im Unternehmen hinweg verwendet werden.

Weiterführende Literatur, Studien und Normen stellen wir zentral in unserem Literaturbereich bereit. Dort finden Sie eine kuratierte Auswahl relevanter Standards, wissenschaftlicher Veröffentlichungen und regulatorischer Dokumente zu Metadatenmanagement, Interoperabilität und Datenregulierung.

Kommentare