
Den rechtlichen Minenfeldern navigieren: Wie Datenkataloge die Compliance von Unternehmen verankern
- Reto Schneider

- vor 4 Tagen
- 3 Min. Lesezeit
In der aktuellen globalen Regulierungslandschaft stehen grosse multinationale Konzerne vor einer beispiellosen Herausforderung: der Verwaltung umfangreicher, fragmentierter Datenbestände bei gleichzeitiger Einhaltung strenger Vorschriften wie der Datenschutz-Grundverordnung (DSGVO), des California Consumer Privacy Act (CCPA) und des EU AI Act. Daten sind längst nicht mehr nur ein strategisches Asset – ohne wirksame Governance können sie schnell zu einer erheblichen rechtlichen Haftung werden.
Viele Unternehmen kämpfen mit fragmentierten Datenlandschaften, die über Jahre durch Akquisitionen, regionale Geschäftsbereiche und voneinander getrennte IT-Systeme entstanden sind. Dadurch werden sensible Informationen häufig mehrfach gespeichert, unzureichend dokumentiert oder an Orten abgelegt, die den Compliance- und Rechtsteams nicht bekannt sind. Diese fehlende Transparenz erschwert den Nachweis regulatorischer Konformität, die Bearbeitung von Betroffenenanfragen sowie die Bewertung neuer Vorschriften wie des EU AI Act. Ohne eine zentrale Sicht auf die Unternehmensdaten wird Compliance zu einer reaktiven, kostenintensiven und zunehmend risikobehafteten Aufgabe.
Ein moderner Enterprise Data Catalog begegnet diesen Herausforderungen, indem er ein zentrales Inventar aller Datenbestände, Metadaten, Verantwortlichkeiten und Governance-Richtlinien schafft. Durch automatisierte Datenerkennung, Klassifizierung und Nachverfolgung der Datenherkunft erhalten Unternehmen Transparenz darüber, wo Daten gespeichert sind, wie sie genutzt werden und wer dafür verantwortlich ist. Diese Transparenz reduziert Compliance-Risiken und erleichtert die Einhaltung regulatorischer Anforderungen. Gleichzeitig verbessert die zentrale Transparenz die Datennutzung für Analysen, KI-Initiativen und operative Entscheidungen.
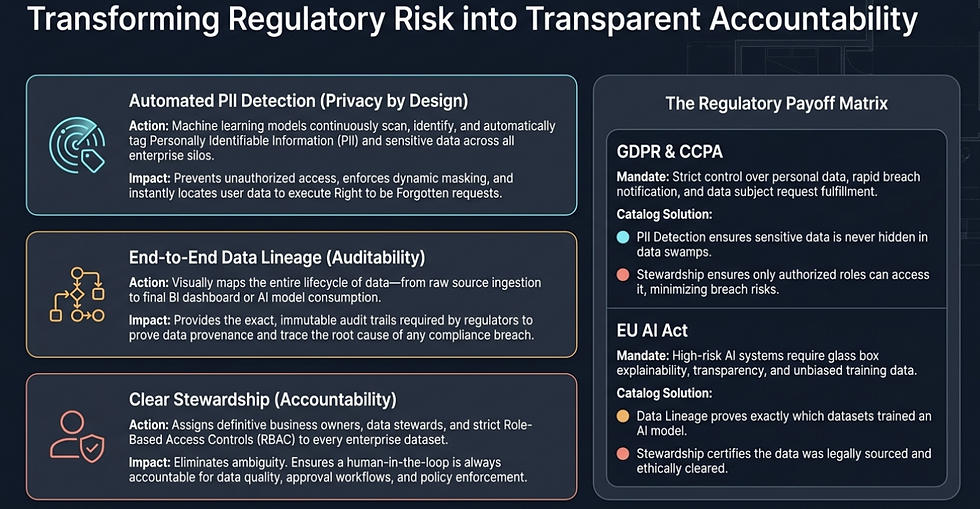
Automatisierte Erkennung: Das Ende der “Compliance durch Raten"
Eines der grössten Risiken für jedes multinationale Unternehmen ist die Existenz von “Dark Data" – sensible Informationen, die in vergessenen Datensilos schlummern. Moderne Datenkataloge lösen dieses Problem durch automatisierte Erkennung sensibler Daten. Mithilfe KI-gesteuerter Algorithmen scannen diese Werkzeuge verschiedenste Datenquellen – von ERP-Systemen bis hin zu IoT-Geräten – um personenbezogene Daten (PII), gesundheitsbezogene Daten (PHI) sowie andere unternehmenskritische Informationen zu identifizieren und zu kennzeichnen.
Durch die Klassifizierung, die Vergabe persistenter Labels wie “Vertraulich" oder “Eingeschränkt", stellt der Katalog sicher, dass rechtliche Schutzanforderungen für jeden Nutzer sichtbar sind, bevor auf die Daten überhaupt zugegriffen wird. Diese proaktive Klassifizierung ist unerlässlich, um dem Recht auf Vergessenwerden nachzukommen – denn ein Unternehmen kann keine Daten löschen, die es nicht finden kann.
Nachvollziehbarkeit und die Bedeutung der Datenherkunft
Für Rechts- und Prüfungsteams ist das Wissen darüber, welche Daten vorhanden sind, nur die halbe Miete; man muss auch nachweisen können, woher sie stammen und wie sie verarbeitet wurden. Automatisierte Datenherkunft “Lineage“ liefert “Data Provenance" und visualisiert den vollständigen Weg eines Datensatzes von seiner Quelle über jede Transformation bis hin zum endgültigen Nutzungspunkt.
Dieses Mass an Nachvollziehbarkeit ist für Auditierbarkeit und Rechenschaftspflicht unerlässlich. Wenn eine Aufsichtsbehörde einen Finanzbericht oder eine KI-gestützte Entscheidung hinterfragt, stellt der Datenkatalog einen umfassenden Prüfpfad von Metadatenänderungen und Zugriffsmustern bereit. Diese Transparenz gewährleistet, dass die “Entscheidungsherkunft" erhalten bleibt, und reduziert das Risiko empfindlicher Bussgelder aufgrund mangelnder Rechenschaftspflicht erheblich.
Governance als rechtliche Schutzmassnahme
Der rechtliche Mehrwert eines Datenkatalogs ist tief in Verantwortung und Eigentümerrollen der Daten verankert. Durch die formale Zuweisung von Data Owners und Data Stewards für jede kritische Geschäftsdomäne stellen Unternehmen sicher, dass es einen benannten Verantwortlichen gibt, der für die rechtliche Compliance und die Qualität eines Datensatzes zuständig ist.
Darüber hinaus werden erfolgreiche Implementierungen durch eine Richtlinie für Datenkatalog- und Metadatenverwaltung auf Führungsebene vorangetrieben. Diese Richtlinie schreibt vor, dass Metadaten als kritische Ressource behandelt werden, sodass der Zugriff nur über verwaltete Workflows und nicht über statische, weitreichende Berechtigungen gewährt wird.
Dieses Prinzip des “Access Control as a Service" stellt sicher, dass sensible Daten ausschliesslich für ihren vorgesehenen und rechtmässigen Zweck genutzt werden.
Fazit
Für moderne Unternehmen dient der Datenkatalog als “Kontextschicht", die abstrakte rechtliche Anforderungen mit der technischen Realität verbindet. Durch die Zentralisierung der Governance, die Automatisierung der Klassifizierung und die Bereitstellung einer lückenlosen Nachvollziehbarkeit verwandelt der Katalog Compliance von einer manuellen, reaktiven Bürde in einen strategischen Vorteil. Kurz gesagt: Unternehmen, die ihre Metadaten beherrschen, schaffen die Grundlage für nachhaltige Compliance, vertrauenswürdige KI und datengestützte Innovation.
Jetzt handeln
Kontaktieren Sie uns noch heute und erfahren Sie, wie unsere Metadaten-Lösungen Ihr Unternehmen compliant, wettbewerbsfähig und zukunftssicher machen.
Weiterführende Literatur, Studien und Normen stellen wir zentral in unserem Literaturbereich bereit. Dort finden Sie eine kuratierte Auswahl relevanter Standards, wissenschaftlicher Veröffentlichungen und regulatorischer Dokumente zu Metadatenmanagement, Interoperabilität und Datenregulierung.


Kommentare